The Status Server serves as an open repository of status and state information available to any client within the CFHT network. Clients are able to view, create, update, remove or monitor information within the Status Server. In some respects, the Status Server could be thought of as a shared memory pool for multiple clients.
The Status Server is currently used at both CFHT and Pan-STARRS. TMT is currently evaluating HornetQ and Redis as Status Server type systems to handle event and telemetry information.
Information within the Status Server is stored as a hierarchy of name-value pairs. Only current status information is stored. At the time this document is written there are over 42,000 unique name-value pair status entries contained within the Status Server at CFHT. Each element in the Status Server is limited to a maximum data size of 255 characters.
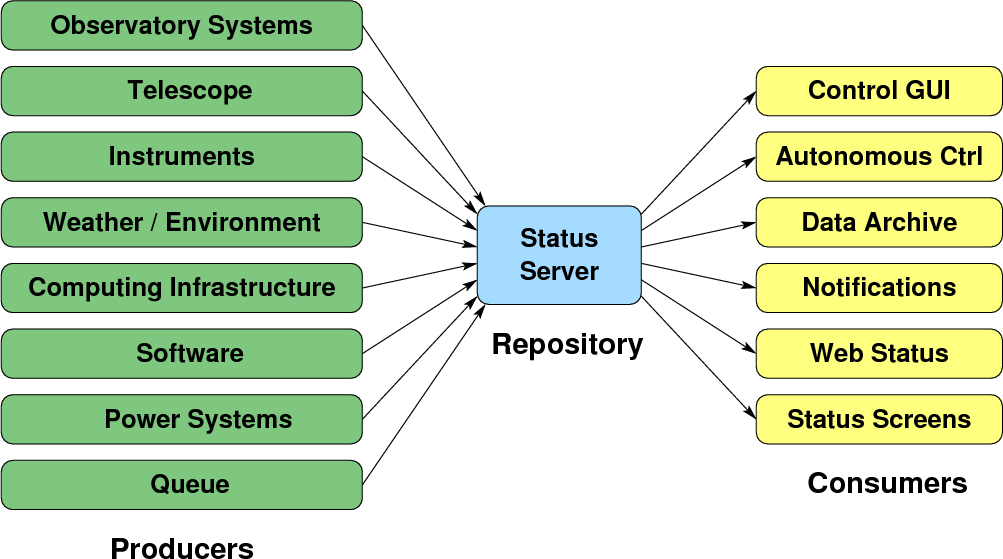
Figure 1 shows a diagram of the systems within CFHT that produce status information as well as the clients that utilize this information. Before the Status Server existed at CFHT, status information was largely contained within each individual subsystem. If a client was interested in access to status it would be necessary to retrieve this information using customized solutions for each system. In 2002 it became clear that a general solution was necessary to consolidate status data into a central repository and the Status Server was designed and developed.
At this point virtually all the critical systems at CFHT have telemetry and status information published in the Status Server. Figure 1 shows the list of status producers. This can be event further broken down by category.
Each of the producers noted earlier either directly publish information to the Status Server or helper applications were developed to query and publish to the Status Server on a periodic basis. An example of such a utility is the software program ``abss''. The ``abss'' program is used to query Allen-Bradley PLCs and publish status information from registers contained within the PLCs to the Status Server.
Information is usually published to the Status Server at a pre-defined polling interval, depending on the source system, or it is published whenever the information is changed. In order to ensure that status information remains valid, it is possible to assign a lifetime to each piece of status. For example, the dome shutter status information is retrieved from the PLC at a 1 Hz frequency. Each of dome shutter status items have a lifetime of 60 seconds. A consumer of dome shutter status will receive a status value of ``EXPIRED'' for any object that hasn't been updated in over 60 seconds.
On the other side of the Status Server in Figure 1 are the consumers of status information.
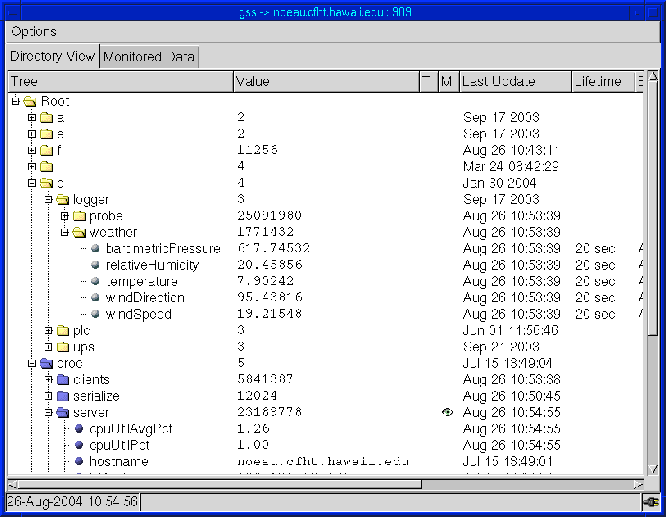
Objects within the Status Server are grouped together in a ``tree-like'' fashion patterned after the UNIX file system. As a result, it is possible for a client to traverse and manipulate objects within the Status Server much like traversing a directory tree and manipulating files in a file system. Objects within the Status Server can be referenced either via a fully qualified directory path/object name combination, or a relative path-name combination. In order to manage relative path references, a current path is maintained for each client connection. Rules to determine whether a path-name combination is expressed as an absolute path or relative path are applied the same way they are in a UNIX file system. A visual example of the type of structure used to hold Status Server information is shown in figure 2. This example is a screen shot taken from the Status Server browsing client ``gss''.
The Status Server is currently running on an older Linux machine and easily handles on average over 2,000 requests per second. Benchmark testing indicates that the Status Server could handle upward of 100,000 transactions per second on newer hardware. The Status Server is a single-threaded process so this performance is isolated to a single core within a CPU on the host computer.
The Status Server was designed to be simple and only focus on supporting the publishing, retrieval and monitoring of name-value pair information. Notifications, archiving, and other features are implemented within clients of the Status Server. As a result, it has been possible to create a small, robust, high-performance solution. The software itself hasn't been modified since 2011 and has only been restarted when it has been necessary to reboot the host computer. This is important since the Status Server is an integral part of the operations and observing environment.